Urban Sound Classification using Machine Learning: Data Processing
The Urban Sound dataset provides 8,732 audio files formatted as .wav, in total 7GB.
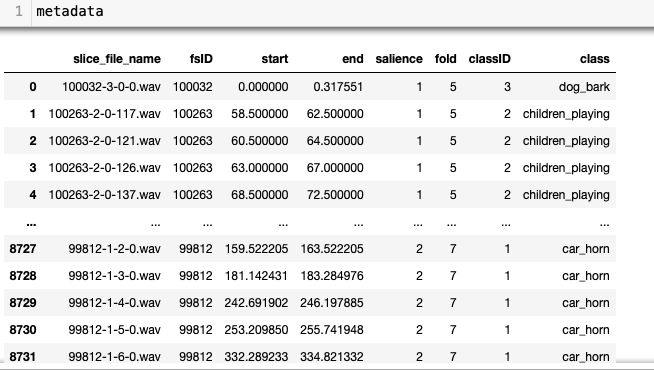 According to the authors, the audio files were collected from
freesound.org, where
the source of each audio file come from and it is recorded in
the 'fsID' column in the metadata table. The duration of each audio can be
obtained from 'end' - 'start', which gives maximum 4 second. The gun shot sounds are shortest.
According to the authors, the audio files were collected from
freesound.org, where
the source of each audio file come from and it is recorded in
the 'fsID' column in the metadata table. The duration of each audio can be
obtained from 'end' - 'start', which gives maximum 4 second. The gun shot sounds are shortest.
According to the authors, the audio files were collected from
freesound.org, where
the source of each audio file come from and it is recorded in
the 'fsID' column in the metadata table. The duration of each audio can be
obtained from 'end' - 'start', which gives maximum 4 second. The gun shot sounds are shortest.
To carry out the machine learning, we need input and algorithm. Can we use
the wav files as input? Even without knowing the audio features, immediate answer is 'maybe not' because of the file size.
The running time for training will be very long.
Then, what and how to extract from the wav files?
Audio data vs. MFCC
We took the dataset and ran it through librosa libraries to convert the wav files into MFCC files. The Mel-Frequency Cepstral Coefficients (MFCC) is a way of capturing the spectrum of the voice (phoneme) so that it can used in voice recognition and machine learning.
import librosa.display
import matplotlib.pyplot as plt
import IPython.display as ipd
def display_wav(signal,fn):
librosa.display.waveplot(signal, sr=sr)
plt.xlabel("Time")
plt.ylabel("Amplitude")
plt.savefig(fn, Bbox='tight')
plt.show()
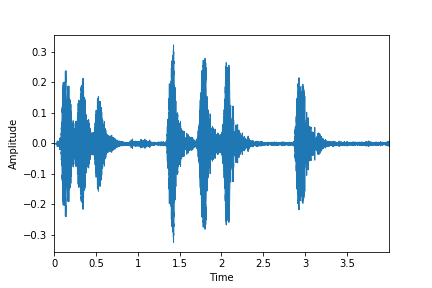
The following graphs and sounds show how much MFCC contains the original data.
Dog_bark: orginal
signal, sr = librosa.load("7383-3-0-0.wav", sr=22050)
display_wav(signal, '../images/dog_bark_plot.png')
Dog_bark: reversed
import soundfile as sf
mfccs = librosa.feature.mfcc(signal,sr=sr,n_mfcc=13)
wav = librosa.feature.inverse.mfcc_to_audio(mfccs)
display_wav(wav, '../images/dog_bark_reversed.png')
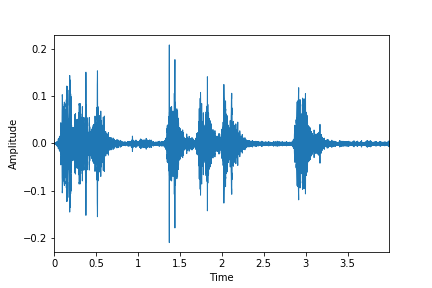
When n_mfcc=40, the reconstructed sound is this, which sounds much closer to the original:
MFCC data
The returned MFCC from librosa.feature.mfcc() is a two-dimensional array of integers.
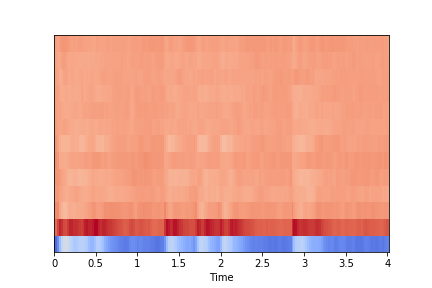 In the image, the vertical height is determined by the number of coefficients(= n_mfcc)
and the width is determined by the sample rate(sr) and duration. The left image has n_mfcc=13 as height,
and 173 as width from sr=22,050 and duration=4 sec. Each small square inside represents a number(amplitude).
The returned MFCC has, in this example, a two-dimensional array of 13 by 173.
In the image, the vertical height is determined by the number of coefficients(= n_mfcc)
and the width is determined by the sample rate(sr) and duration. The left image has n_mfcc=13 as height,
and 173 as width from sr=22,050 and duration=4 sec. Each small square inside represents a number(amplitude).
The returned MFCC has, in this example, a two-dimensional array of 13 by 173.
With these parameters, each audio file outputs 2249 numbers,
therefore in total the sample for
the machine learning algorithm can be a table
of 8,732 rows and 2,249 columns. First, we used pyspark-jbdc query to store the
table in AWS-RDS PostgresSQL. We faced an
error,
 saying the query has the limit as 1600 columns.
saying the query has the limit as 1600 columns.
saying the query has the limit as 1600 columns.
Creating Samples from MFCC
The goal of dataprocessing is to reduce the column size without losing important audio
features. We came up with three types of data processes constructing 'Sample 1, 2, 3':
Sample 1
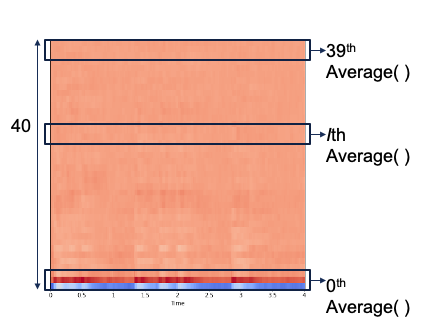
First, we focused on reducing the size by taking the average of the numbers
in the MFCC vector. Then each vector gives one scalar value, which might lose information.
We increased n_mfcc as 40, following each audio file produces 40 values. In total,
we obtained a sample table of the size 8,732 rows and 40 columns.
We carried out
experiment 1
Sample 2
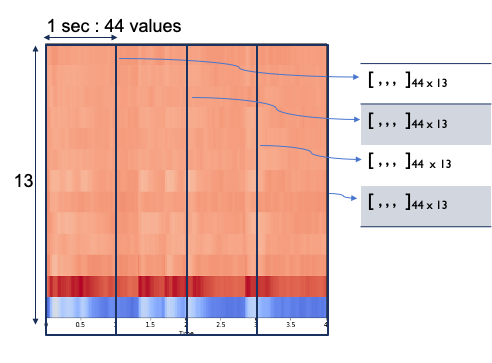
The second sample was taken from all the numbers in mfcc vector.
by setting n_mfcc=13.
We sliced each audio file to 1 second segment.
This one second audio data gives 44 values(from sr=22,050) for each mfcc vector.
So, 4 second length audio file produces 4 rows,
each row has 44 by 13 matrix, when it is flattened, 572 length vector.
We obtained a sample table of the size 30,825 rows and 574 columns.
We carried out
experiment 2
Sample 3

When we run the Sequential model with previous samples,
still we were experiencing low accuracy with dropout and
regulations. In the published paper of this original work,
the authors mentioned the statistical values of mfcc vectors.
Following their idea, we used scipy.stat.describe() method, returning
min, max, mean, var, skewness and kurtosis.
With n_mfcc= 30, each audio file produces 30 minimums, 30 maximums, and so on, which makes 180 length vector. So, the third input data has this form of table.
Therefore, we obtained a sample table of the size 8,732 rows and 180 columns.
With sample 3, we carried out
experiment 3
Data Processing Overal Diagram
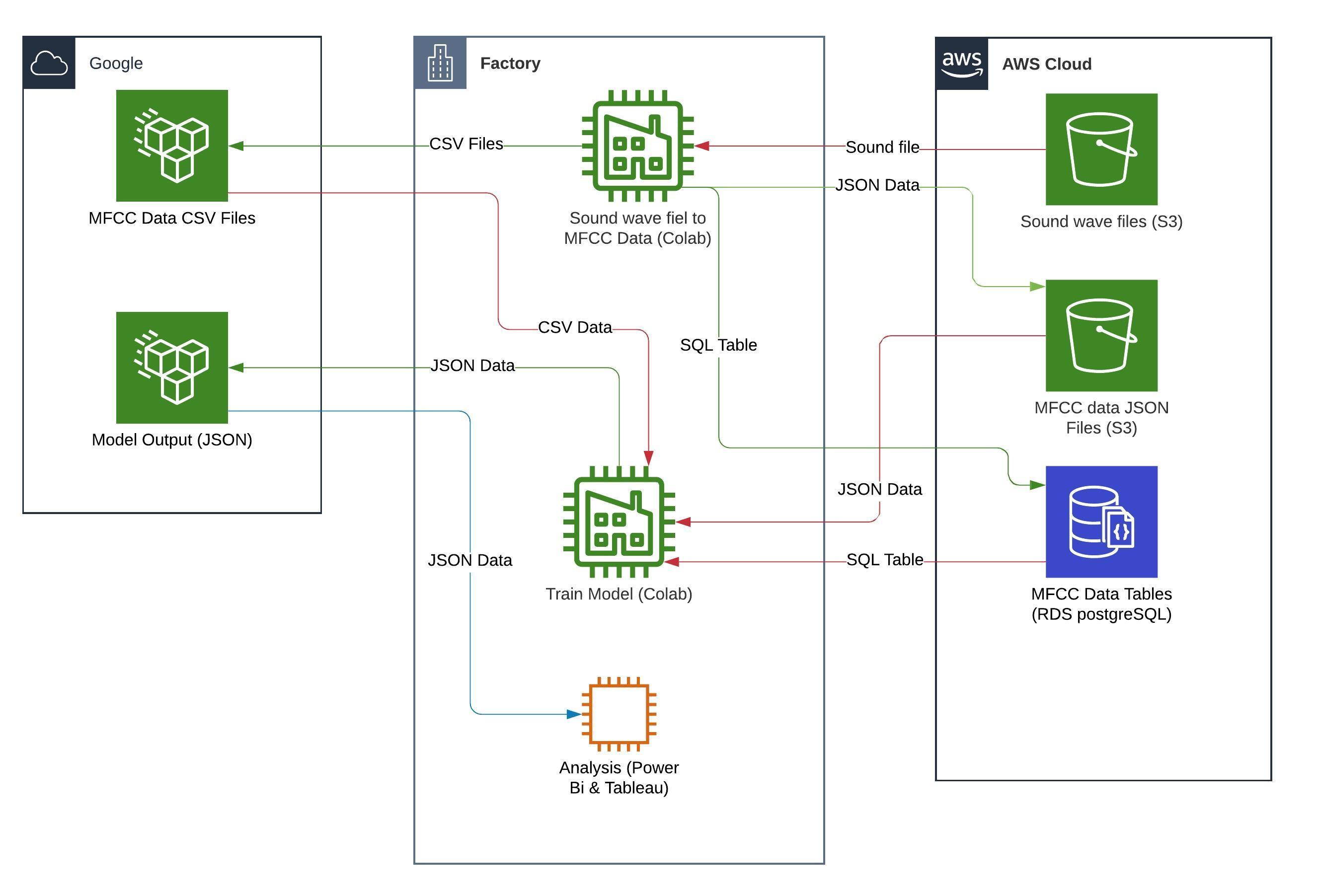
Eunjeong Lee, ejlee127 at gmail dot com, last updated in Nov. 2020